這幾天我們做完了一個完整的文本分類的 transformer 了,但是我們做的內容,都是直接呼叫人家做好的 pre-trained model。其訓練的資料內容都是別人的,都不是自己的。今天我們就來用自己的 dataset,來微調別人的 pre-trained model ,這樣子就可以得到屬於自己 domain knowhow 的 model 了。
今天講的內容就是會之前在談 dataset 和 tokenizer library 的應用,如果不熟的話,可以回去看前面的內容。
poem-sentiment dataset 吧!from datasets import load_dataset
sentiment = load_dataset("poem_sentiment")
sentiment
可以看到這個 dataset 長成這樣
DatasetDict({
train: Dataset({
features: ['id', 'verse_text', 'label'],
num_rows: 892
})
validation: Dataset({
features: ['id', 'verse_text', 'label'],
num_rows: 105
})
test: Dataset({
features: ['id', 'verse_text', 'label'],
num_rows: 104
})
})
import pandas as pd
sentiment.set_format(type="pandas")
df = sentiment["train"][:]
df.head()
會看到下面的結果。
id verse_text label
0 0 with pale blue berries. in these peaceful shad... 1
1 1 it flows so long as falls the rain, 2
2 2 and that is why, the lonesome day, 0
3 3 when i peruse the conquered fame of heroes, an... 3
4 4 of inward strife for truth and liberty. 3
int2str 來看看 labels 長什麼樣。def label_int2str(row):
return sentiment["train"].features["label"].int2str(row)
df["label_name"] = df["label"].apply(label_int2str)
df.head()
會得到:
id verse_text label label_name
0 0 with pale blue berries. in these peaceful shad... 1 positive
1 1 it flows so long as falls the rain, 2 no_impact
2 2 and that is why, the lonesome day, 0 negative
3 3 when i peruse the conquered fame of heroes, an... 3 mixed
4 4 of inward strife for truth and liberty. 3 mixed
labels = sentiment["train"].features["label"].names
print(labels)
import matplotlib.pyplot as plt
df["label_name"].value_counts(ascending=True).plot.barh()
plt.title("Number of labels")
plt.show()
會看到這是一個很不平均的 dataset。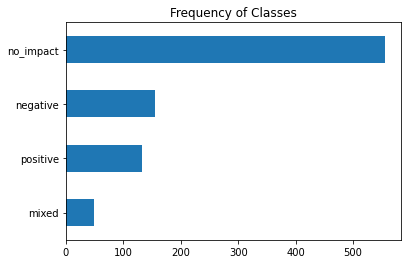
sentiment.reset_format()
from transformers import AutoTokenizer
model_name = "distilbert-base-uncased" # 第三天預設的distilbert-base-uncased-finetuned-sst-2-english用這個
tokenizer = AutoTokenizer.from_pretrained(model_name)
map() 的慣例。def tokenize(batch):
return tokenizer(batch["verse_text"], padding=True, truncation=True)
map() 把資料集做分詞sentiment_encoded = sentiment.map(tokenize, batched=True, batch_size=None)
next(iter(sentiment_encoded["train"])) #忘記這裡為什麼要用 next(iter())才能看到印出來的資料,可以回去看載入極巨大資料篇
可以看到印出來這樣子的結果,代表已經做完分詞啦:
{'id': 0,
'verse_text': 'with pale blue berries. in these peaceful shades--',
'label': 1,
'input_ids': [101,
2007,
5122,
2630,
22681,
1012,
1999,
2122,
9379,
13178,
1011,
1011,
102,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0],
'attention_mask': [1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
1,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0]}
valid_ds = sentiment["validation"]
valid_ds["label"][:]
以上就是資料處理的部份,是不是很簡單呢!明天就來把這個 dataset 丟進去 transformer 做訓練吧!


 iThome鐵人賽
iThome鐵人賽